




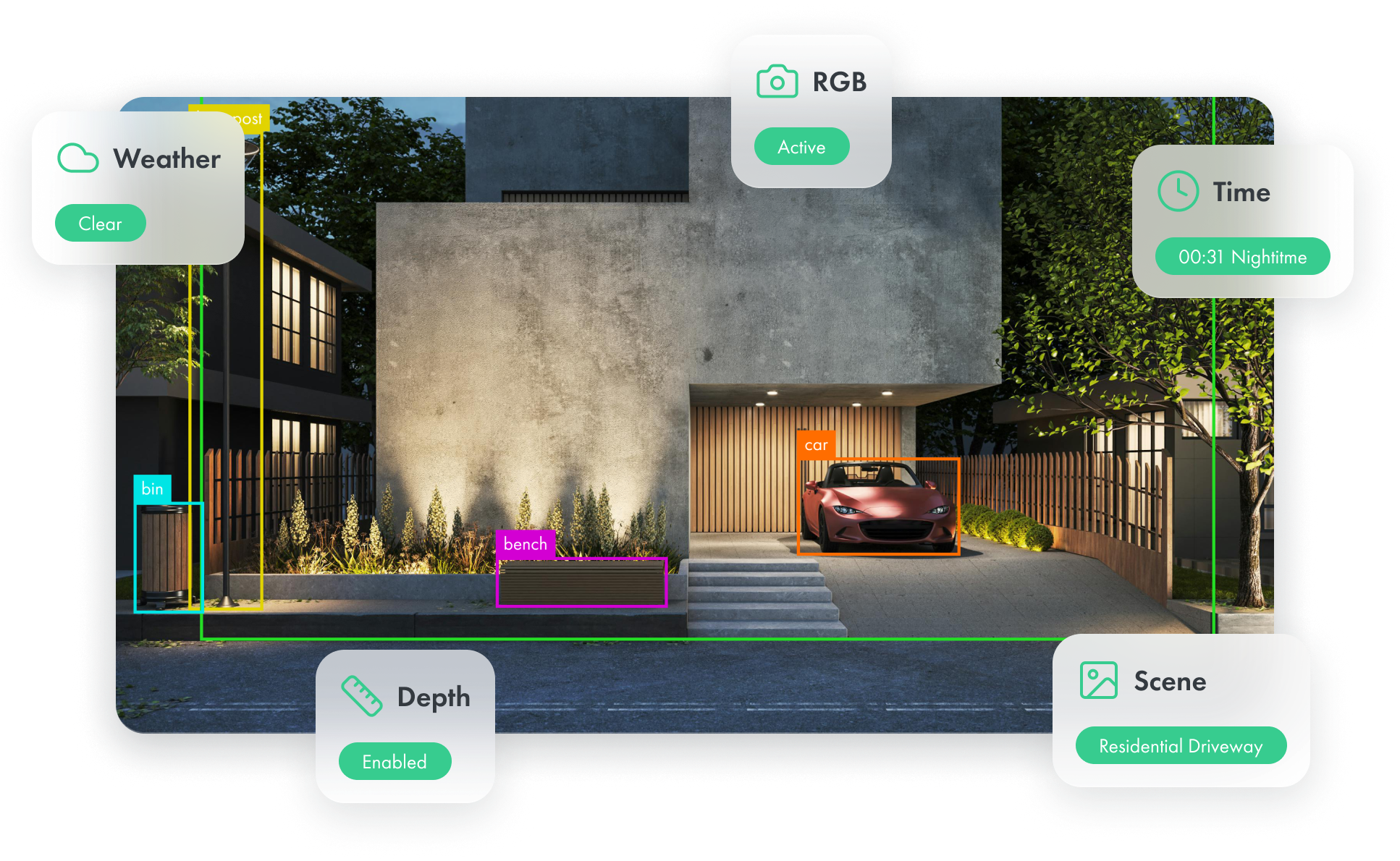



Computer vision teams hit the same wall again and again.
Real world data is slow,
expensive, and biased
expensive, and biased
Labeling takes time and
errors creep in
errors creep in
Privacy and governance rules add friction and slow delivery
Vivid 3D replaces the bottleneck with controlled, repeatable dataset generation from 3D and simulation.
You can cover the cases you actually need, including rare and messy scenarios.
High coverage testing:
Simulate diverse environments and generate the exact data you need in minutes.



















