
Diego Santos
Technical blogger
How to Manage Your 3D Content Effectively and Efficiently
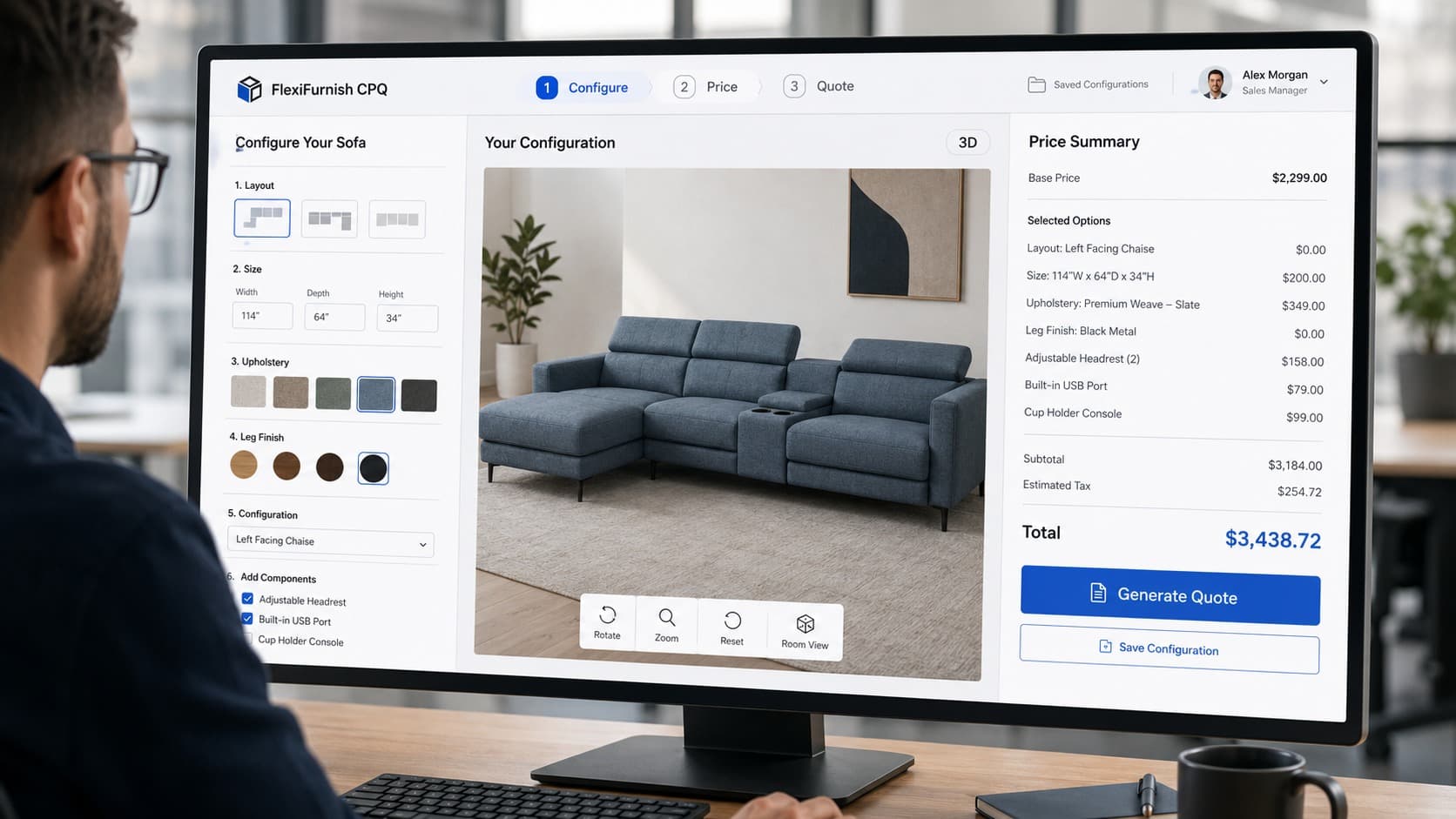
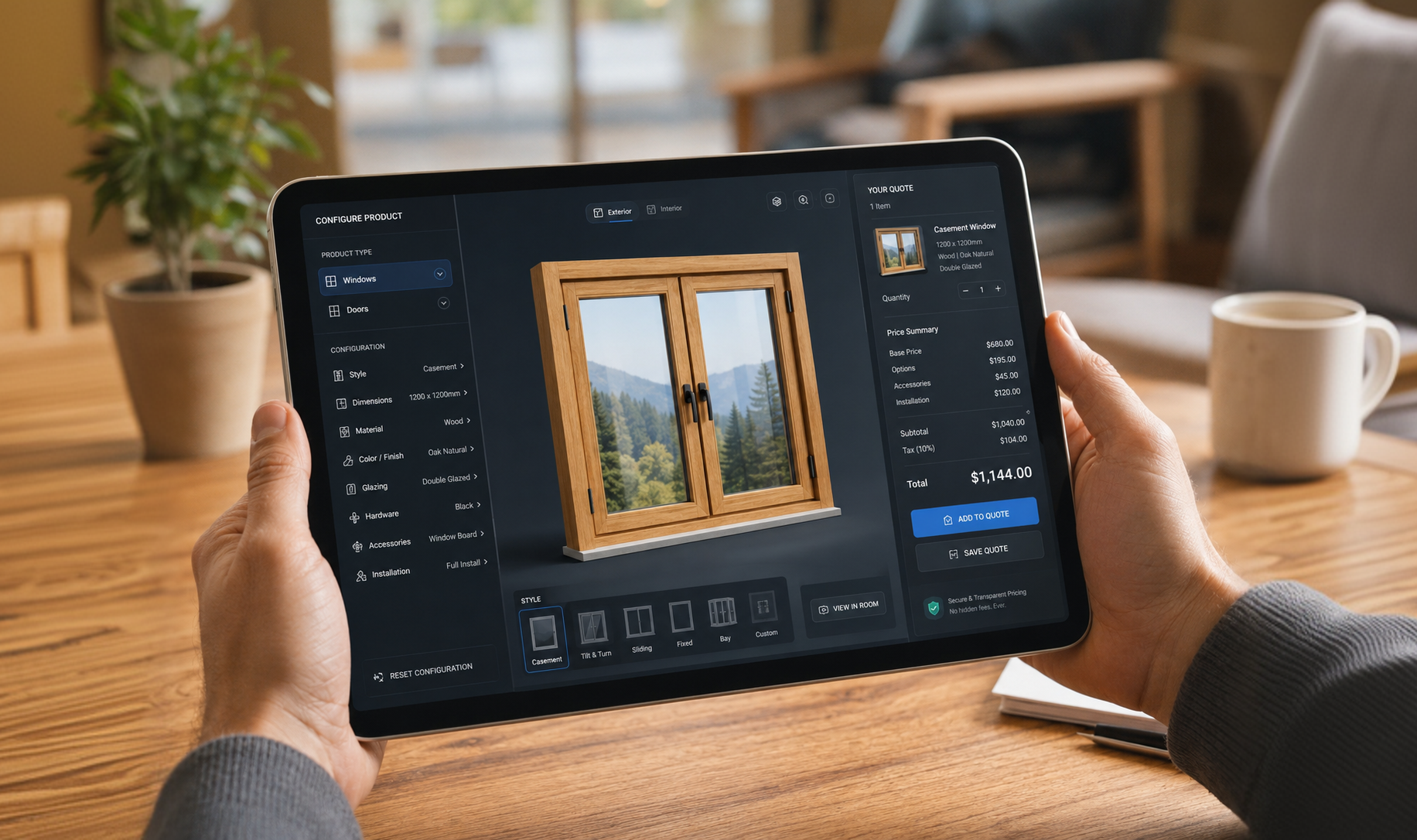
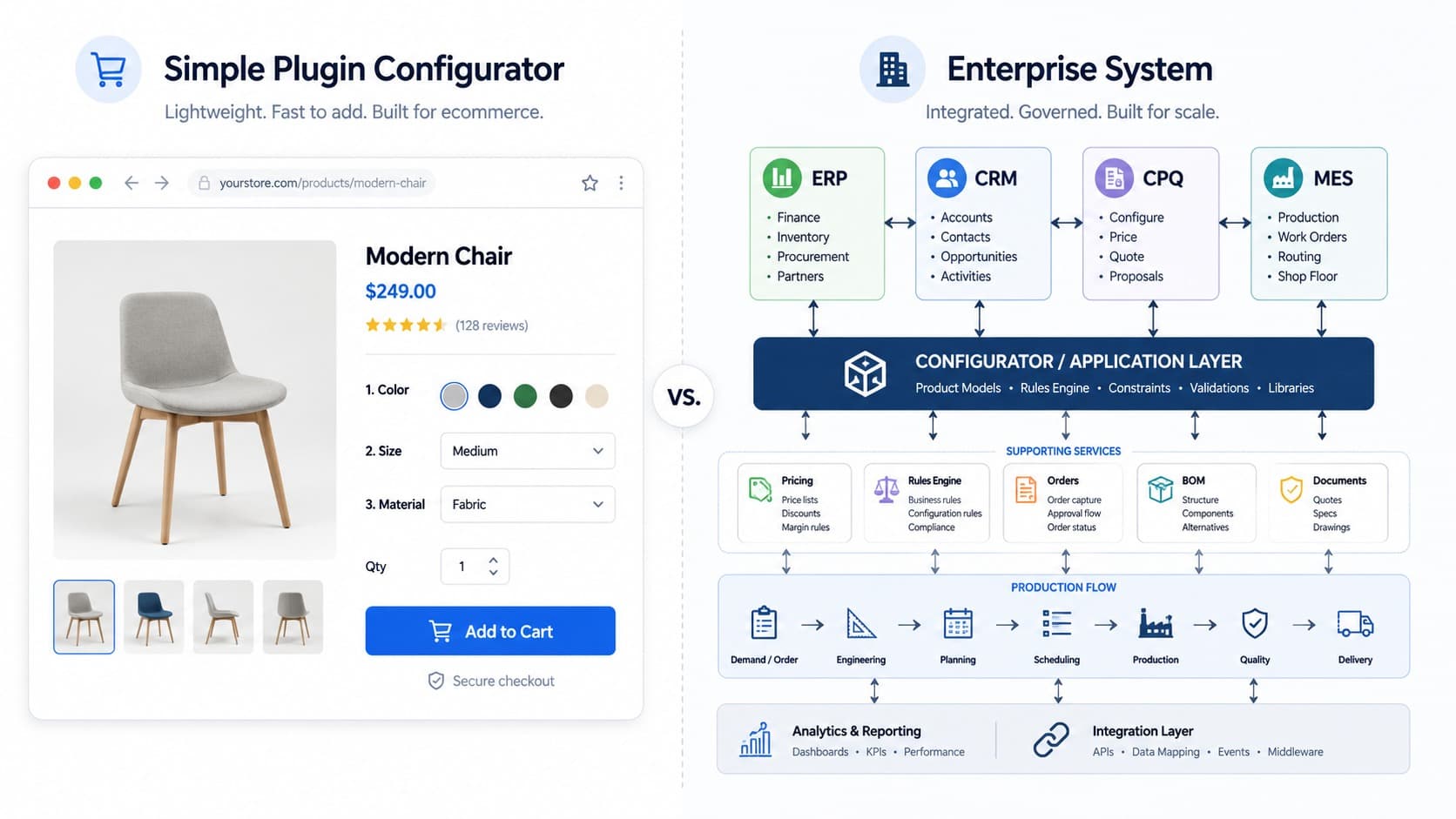
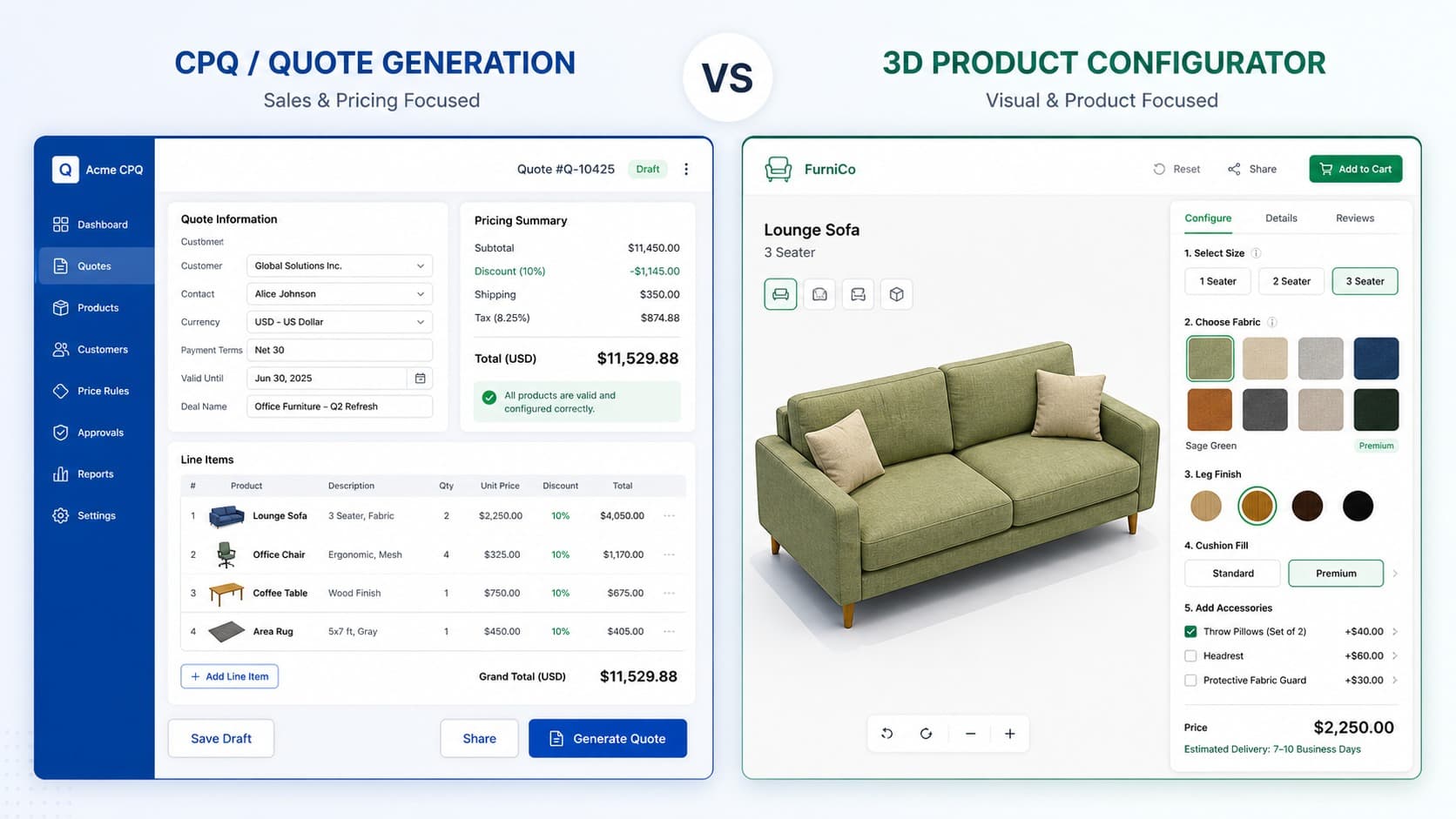
Managing 3D content effectively is really about replacing “file chaos” with a calm, repeatable system that anyone on the team can follow, even beginners. When you centralize your 3D assets in one cloud based source of truth, apply consistent naming, and add rich metadata like format, use case, polygon count, and texture size, your library becomes searchable, reusable, and safe to scale.






.png)


.png)







.png)
