How Synthetic Data Fits Into a Broader Visual Data Platform

Quick Summary. The Role of Synthetic Data in the AI Lifecycle
Synthetic data serves as a scalable engine within a visual data platform, moving through four key stages. In the creation phase, platforms move from passive camera capture to active 3D rendering and generative AI to produce photorealistic, customizable datasets entirely on demand. No camera crews required. In the structuring phase, synthetic pipelines eliminate the manual labeling bottleneck by producing perfect automated metadata including pixel-level masks, depth maps, keypoints, and 3D bounding boxes, without a single human squinting at a screen. In the improvement phase, teams close real-world gaps by simulating rare, dangerous, or practically impossible-to-capture edge cases, and by intentionally balancing scenario coverage to reduce model blind spots. In the training phase, synthetic enables hybrid training workflows where models learn broad variation from large synthetic corpora and then become properly grounded in reality through targeted fine-tuning on real data, guided by a continuous feedback loop.
The framing I keep coming back to is this. Synthetic data for computer vision is not just “more data.” In a modern AI training data pipeline, synthetic becomes a controllable production system that lives inside the visual data platform architecture, sitting alongside capture, labeling, governance, and model iteration. It is not a workaround. It is the architecture.
One clarification that matters for the rest of this article: when I say visual data platform, I do not mean “a place to store images.” I mean an end-to-end system that can create, structure, govern, and operationalize visual data across the full model lifecycle. In practical terms, a platform earns that label when it can do five things reliably: ingest and manage real and synthetic assets, generate or simulate new data on demand, produce and validate ground truth at scale, version datasets with clear lineage and export them into training pipelines, and close the loop by turning model failures into the next data requirements. That is the context where synthetic data in visual data platforms becomes a compounding advantage rather than a one-off experiment.

Beyond Cameras. The Evolution of Visual Data Platforms
Many visual data platforms began life as very sophisticated filing cabinets. They ingested images and video from cameras, stored them carefully, helped teams label them with admirable patience, and passed the dataset along to training. That workflow can get a team surprisingly far, right up until the point where it absolutely cannot.
Collection is slow. Labeling quality varies by annotator, by vendor, by the hour of the day, and by how much coffee the annotator has had. Edge cases are scarce by definition. And every new environment changes the data distribution in ways that yesterday’s collection cannot predict or fix.
What is changing is the platform’s fundamental role. The most effective platforms today behave less like libraries and more like factories. Instead of only cataloging what the world happened to produce on a given Tuesday, they help teams produce what the model actually needs to see. That is the conceptual shift from collector to creator, and in my view it is precisely where synthetic data in visual data platforms stops being an interesting experiment and becomes a core requirement.
I ran into a simple idea early on that still holds up. The real advantage of synthetic data is not perfect realism. It is control. Instead of waiting for the world to produce the right examples, you decide what the model needs to learn and you generate that coverage on purpose. That shifts the core question from “does this look real?” to “are we teaching the model the right variation, in the right proportions, for production?”
This shift is also driven by a hard truth that computer vision teams run into, usually at the worst possible moment. That truth goes by the name of the sim-to-real gap. If your training data is too clean or too uniform, the model learns shortcuts that collapse spectacularly in production. If your synthetic data looks like a polished demo render from 2014, performance tends to evaporate when it meets real sensor noise, messy backgrounds, occlusion, and genuine wear and tear. Closing that gap is less about chasing photorealism everywhere and more about engineering the right variety, with validation loops that keep synthetic honest.
A dataset that is large but not representative is not helpful. A pipeline that cannot explain what changed between dataset versions is not trustworthy. A platform that cannot connect model failures back to targeted data generation is not reliable. These are not marketing ideas. They are operational requirements that define whether a visual AI system actually works in the field.
One more operational requirement is worth calling out explicitly because it tends to hide in the background until something goes wrong: data operations. If a platform cannot tell you which scenes, parameters, label schemas, and export formats produced a given dataset, you cannot reproduce a training run, you cannot debug regressions, and you cannot prove what changed when a model improves. Or collapses. In other words, visual data platform architecture is not only about generation. It is about repeatability, lineage, and auditability across the entire training data pipeline.
The Four Pillars of a Synthetic-Enabled Platform
A synthetic-enabled platform is not defined by having one impressive generator. It is defined by an integrated loop that turns requirements into data, turns data into models, and turns model performance back into refined requirements. The four pillars below describe the visual data platform architecture that makes synthetic scalable and responsible, rather than experimental and quietly unreliable.
Data Generation. From Capture to Creation
Generation is where the platform stops waiting for the world to cooperate. It starts with the question “What does this model need to see to be reliable in production?” and works backward into controlled scenario creation. Surprisingly, this turns out to be more useful than waiting for the right forklift to drive past the camera at the right angle in the right lighting.
In practice, a platform typically supports two complementary approaches. The first relies on 3D simulation and rendering, where teams use engines such as Unity or Unreal to build scenes that can be parameterized and varied at scale. Camera position, focal length, exposure, motion blur, lighting type, surface materials, clutter level, background domains, and sensor noise all become controllable variables. Object poses and interactions can be varied in ways that are difficult to capture reliably with real cameras. You get environments where labels can be produced automatically, at scale, without negotiating with reality.
The second approach is procedural generation for computer vision. Instead of hand-crafting scenes one at a time, teams define rules and let the system do the rest. For a defect detection system, the rule might be to apply scratch patterns with variable depth and direction, keep the scratch subtle enough to be realistic, place it more often near edges where handling damage is likely, vary the background texture distribution, and include near-misses that resemble defects but are not. For warehouse perception, the rule might be to stack boxes with realistic occlusion patterns, allow partial label visibility, randomize packaging reflectivity, and include torn shrink wrap with plausible geometry. Procedural systems are what allow teams to scale edge case simulation without scaling scene-building labor at the same rate.
From where I stand, this is the most underappreciated shift in how computer vision teams operate. The mental model changes. You stop asking “what did we capture?” and start asking “what do we need the model to understand?” Those are very different questions, and the second one is significantly more useful when you are trying to ship something that works in a warehouse in February and not just in a well-lit studio in October.
A good visual data platform architecture also treats generation outputs as first-class assets, not as disposable files that only matter until the next training run. Scenes, recipes, parameter ranges, sensor configurations, and dataset manifests should be versioned. Otherwise reproducing a training run becomes archaeology, and proving what improved or regressed when a model changes becomes educated guessing.
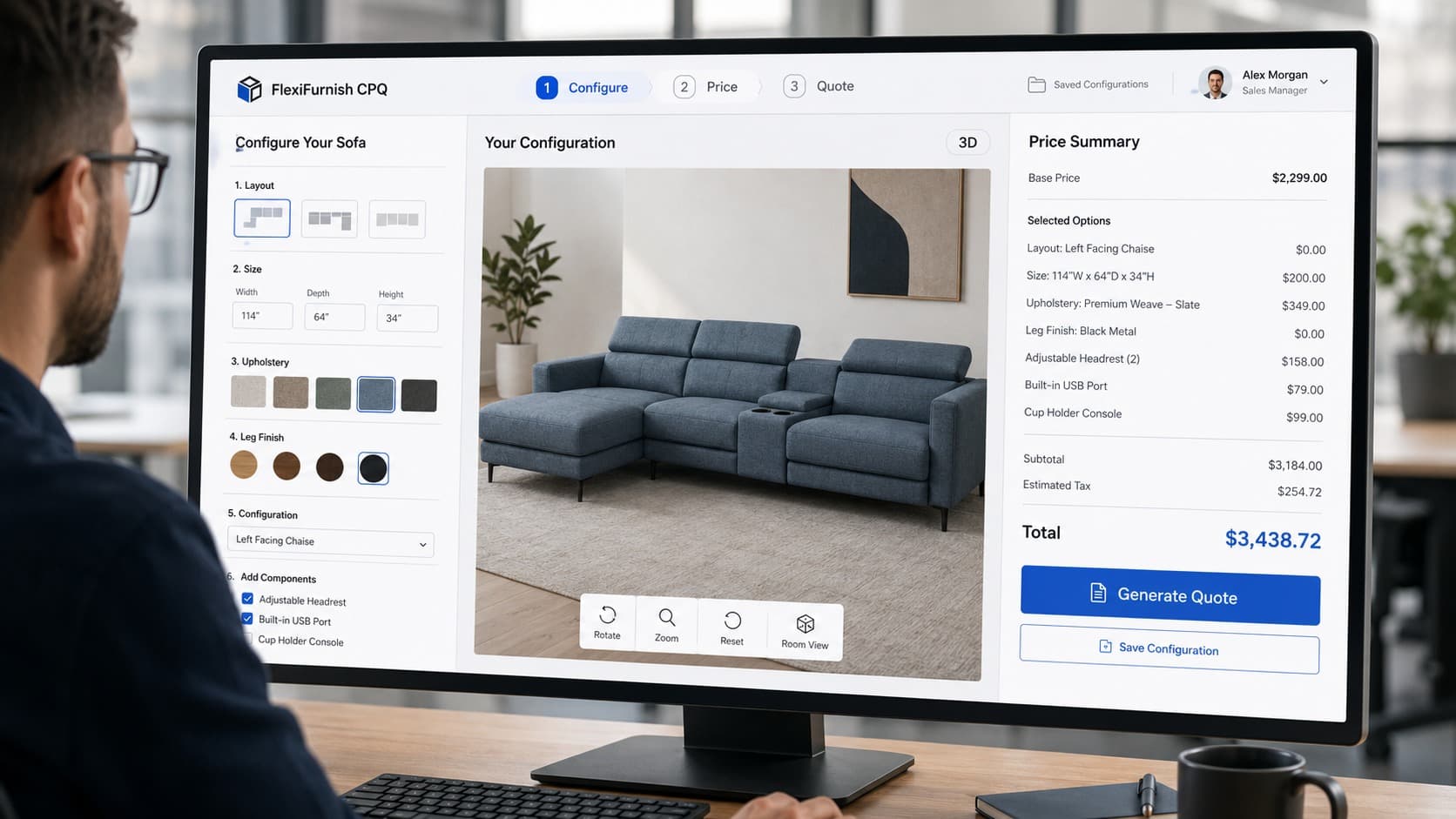
This is also where Vivid 3D’s positioning becomes meaningful in practice. The goal is not simply to “render images.” The goal is to run generation as an industrial workflow: reusable scenario templates, controllable variation, and consistent outputs that slot cleanly into the rest of the platform. When generation is integrated this way, the platform stops producing random piles of synthetic frames and starts producing repeatable training assets that can be regenerated, audited, and improved as the model evolves.

Perfect Labels. Solving the Annotation Bottleneck
If generation is the engine, automated annotation is what makes the engine useful. It is what turns raw pixels into training signal, consistently and at volume, without the cheerful inconsistency that comes with human labeling at scale.
Human labeling is both expensive and noisy. Even highly trained annotators disagree on boundary placement, small object inclusion, and class definitions. That problem becomes acute when pixel-level annotation precision matters for segmentation tasks, when fine-grained defect boundaries are the whole point, or when pose estimation work requires accuracy that human annotators cannot reliably sustain across thousands of images. Beyond quality, there is also speed. Teams often spend more calendar time on labeling than on modeling, which is a peculiar way to allocate engineering effort.
I have seen this pattern play out more than once. A team spends three months building a strong model architecture, then discovers they are going to spend the next five months labeling data before they can actually test anything meaningful. It is not a data problem in the traditional sense. It is a pipeline design problem, and synthetic annotation is the most direct fix available.
Synthetic pipelines eliminate most of that manual work because ground truth can be emitted directly from the scene. When the platform knows the geometry, materials, camera parameters, and object identities, it can output segmentation masks, depth maps, keypoints, 2D bounding boxes, and 3D bounding boxes without ambiguity or fatigue. Annotation becomes a deterministic system output rather than a staffing problem, which changes the math on what is actually possible at scale.
There is a nuance worth stating clearly. “Perfect labels” describes label correctness with respect to the rendered image. It does not guarantee relevance to the real world. A platform still needs quality gates that test whether the synthetic distribution is teaching the right invariances rather than training the model to recognize synthetic artifacts with unusual proficiency. That is why the most mature teams treat automated annotation as part of governance. They validate class taxonomies, label schemas, and downstream export formats early, and they measure dataset health rather than just dataset size.
What can go wrong with synthetic labels? First, perfect ground truth can still be the wrong truth if the synthetic distribution is misaligned with production. Second, models can learn synthetic artifacts like unnaturally clean edges, repeating textures, or unrealistic lighting priors. Third, taxonomy drift breaks training quietly when class definitions evolve but exports do not. The fix is boring but effective: holdout real validation sets, dataset shift checks, schema validation, and a small recurring “realism audit” where you review failure cases side by side.
One practical detail that separates “we generate labels” from “this actually plugs into production” is standardization. The platform needs to output ground truth in formats teams can train with immediately. COCO, KITTI, YOLO-style annotations, or task-specific schemas. Without hand-built conversion scripts becoming a fragile dependency. And it needs to do so with the same discipline as code: schema validation, consistent taxonomy, and dataset manifests that tell you exactly what is inside each version. Automated data annotation is the win, but operational annotation is the difference between a demo and an AI training data pipeline you can trust.
Augmentation and Synthesis. Solving for the Long Tail
Real-world data is not evenly distributed. Most images reflect normal operations, normal lighting, and normal product states. Models fail on the exceptions, and the exceptions are what cost money, reputation, or in some industries, something considerably more serious.
Synthesis is how a platform targets that long tail deliberately. It includes traditional augmentation techniques such as blur, noise, color shift, and background variation, but it goes further by creating scenarios that are rare, dangerous, or effectively impossible to capture at the needed scale through conventional collection.
Consider micro-defects in manufacturing. A seam shift might be rare in a well-tuned production line, but a model still needs to catch it reliably when it appears. A particular type of scratch might only occur during one handling step. If teams wait for enough real examples to accumulate, they risk shipping defects throughout the collection period. Synthetic data for computer vision allows teams to generate controlled defect states calibrated to be subtle and realistic, then produce large volumes of perfectly labeled examples. The model learns from what it needs to know rather than from what happened to occur.
Example from practice. In one defect detection pilot, we had too few real examples of low-contrast scratches to train reliably. We generated synthetic variants by controlling scratch depth, direction, lighting angle, and background texture, then mixed them with a small real fine-tuning set. The first run overfit to clean synthetic edges, so we added sensor noise, mild blur, and more cluttered backgrounds. Replace this with your real numbers: how many real samples you had, how many synthetic you generated, and what metric moved (for example recall on low-contrast defects).
Now consider what practitioners sometimes call “black swan” operational events. In logistics, teams care about rare occlusion combinations and damaged packaging configurations. In automotive and robotics work, edge conditions that are genuinely unsafe to stage repeatedly become training targets. In retail and luxury goods, rare counterfeit signals, unusual material reflections, or wear patterns that only appear in specific circumstances need to be covered. In each case, edge case simulation is not optional. It is the only practical path to managing risk.
Domain randomization is one of the most reliable ways to make synthetic data transfer to the real world. The key idea is to randomize many nuisance factors on purpose, such as lighting, textures, camera settings, backgrounds, clutter, and noise, so the model cannot “cheat” by memorizing a single clean visual pattern. When you do this well, models often generalize better than they do with a simulation that is tuned to look perfectly realistic in one narrow setting, because randomization forces the network to learn the underlying signal that stays stable across conditions. The takeaway is practical: precision in the wrong dimension can hurt you. For transfer, breadth of variation usually beats a perfect render.
Bias mitigation in AI also fits naturally into this pillar, but only when teams treat it as an engineering problem with measurable outcomes rather than a checkbox. Synthetic generation can help rebalance scenario coverage by ensuring that lighting conditions, backgrounds, materials, and object variants are not underrepresented in ways that the original collection never noticed. The important operational point is that teams must define what “balanced” means for their specific task and then test it through evaluation slices rather than assuming that generation alone solves the problem.
A useful way to frame this pillar is “hybrid training datasets by design.” Real data tells you what your deployment environment actually looks like. Synthetic fills in what real data cannot provide fast enough: rare events, controlled stress tests, and deliberate coverage of variation that would otherwise remain accidental. The platform’s job is to make that hybrid mix measurable. Not “we added augmentation,” but “we improved performance on these long-tail slices because we intentionally generated these missing scenarios.”

Optimization. Closing the Loop on AI Development
The biggest mistake teams make with synthetic data is treating it as a one-time dataset purchase. Generate once, train once, ship, and hope. The actual advantage of synthetic data in visual data platforms is not only volume. It is responsiveness. When the platform can generate data as a reaction to model performance, it becomes a system that can improve continuously rather than periodically.
Two mechanisms drive this most effectively. Hybrid training is where synthetic handles broad coverage early in the process and real-world data handles grounding. Synthetic teaches the model the task structure and exposes it to meaningful variance. Real fine-tuning teaches it the true sensor characteristics, background distributions, and real-world artifacts that define production conditions. It reduces the amount of expensive real labeling required while protecting real-world performance, which is a combination that tends to make data teams considerably happier.
Active learning guided generation is the other mechanism worth understanding. When a deployed model fails, or when confidence scores drop in certain conditions, that information should feed directly back into data generation workflows. The platform can translate observed failures into new scenario recipes, then generate targeted synthetic batches that address the specific gap. This turns iteration cycles from months into days because teams are no longer waiting for the world to produce the next useful set of training examples. They are producing those examples themselves, on demand, in response to evidence.
My honest view here is that this closed loop is where the real competitive advantage lives. A team that can identify a failure mode on Monday and have training data addressing it by Wednesday is operating in a fundamentally different way than a team that logs the failure, writes a collection brief, waits for labeling, and reviews results six weeks later. The speed gap compounds quickly.
This only works if evaluation is wired into the loop. If you cannot measure slice performance reliably, fast generation just produces faster confusion. The closed loop needs three basics: a stable test set, slice metrics tied to risk, and a rule for when a synthetic batch is allowed into training.
This is also where a visual data platform architecture must include evaluation and dataset governance as first-class capabilities rather than afterthoughts. Generating endlessly without measurement produces very large datasets that do not improve performance, which is an expensive way to discover that quantity and quality are different things. The platform needs model metrics tied to business risk, dataset versioning, distribution sanity checks against real reference sets, and tests that detect whether the model is learning synthetic artifacts instead of genuine task signals.
Another concept that helps teams run this pillar like infrastructure rather than art is regression testing for data. If you can treat scenario suites as repeatable tests. “Low light + glare + motion blur,” “occlusion over 40%,” “rare defect class at low contrast”. Then synthetic becomes a way to continuously validate the model against known risks. That turns “optimization” into a closed-loop system with guardrails: you do not only train faster, you also catch breakages earlier, because your synthetic scenarios can function as a consistent benchmark that real-world collection cannot reproduce on demand.
Synthetic data is not good because it is synthetic. It is good when it reliably helps the model solve the real task in production. That requires measurement, feedback loops, and honest evaluation rather than the assumption that more generated data is automatically better data.
.png)
Strategic Advantages. Privacy, Speed, and Scale
Synthetic data is typically adopted for three strategic reasons. Each is real, and each becomes real only when properly integrated into the platform rather than bolted on as an afterthought.
Privacy compliance is a frequent driver, and an increasingly urgent one. Synthetic generation can reduce reliance on images containing personally identifiable information because humans, faces, and environments can be generated without capturing real individuals. That is particularly useful in retail, healthcare-adjacent workflows, or any environment where collecting real imagery creates meaningful compliance overhead. Synthetic outputs can also be shared more freely across teams and vendors because there is less risk of exposing real subjects in ways that create legal exposure.
Speed tends to show up second on the strategic list but first in team calendars. When the pipeline can generate and label data automatically, dataset creation shifts from a manual queue that someone has to manage into an automated job that runs while the team focuses on other problems. This is where scaling AI training data with synthetic starts to feel like actual infrastructure, because iteration becomes a routine operation rather than a project milestone with its own planning cycle.
Scale is what separates teams operating at genuine production maturity from everyone else. Scaling with real capture and manual labeling often means scaling headcount, vendor cost, and calendar time in rough proportion. Scaling with synthetic means scaling compute and process discipline instead. That does not mean it is effortless. It means the constraint changes in a way that is more manageable. Teams invest in scenario design, validation, and governance, and they gain the ability to produce targeted coverage at volume whenever business conditions change. That is a meaningfully better position to be in.
One more strategic advantage tends to matter deeply to enterprise teams, even if it is less exciting to talk about: governance and traceability. When synthetic is integrated into the platform, you can document how datasets were produced, what scenarios were included, which label schemas were used, and what changed between versions. That lineage becomes the backbone for compliance reviews, internal model risk management, and the simple reality of debugging production regressions without guesswork.
Conclusion. The Generative Data Factory
A visual data platform without synthetic capabilities increasingly resembles the architecture of a previous era. Cameras and storage help teams remember what the world looked like. They do not help teams systematically prepare for what the model will encounter next month, in the next facility, or under the operating conditions that no one anticipated during the original collection phase.
Synthetic data fits into a broader visual data platform when it is treated as a four-stage system rather than a single tool. Generation creates the scenarios teams need, through 3D engines, procedural generation, and controlled variation. Automated annotation turns those scenarios into structured training signal with pixel-level precision and consistent schemas. Synthesis expands coverage into the long tail, including rare defects, unusual operational states, and domain randomization that improves transfer to real conditions. Optimization closes the loop through hybrid training and feedback-driven iteration, so the platform responds to model failures instead of hoping those failures become less frequent on their own.
What I find compelling about this architecture is that it treats data not as a resource you exhaust but as a capability you develop. The teams I respect most in this space are not the ones with the biggest datasets. They are the ones who can answer the question “what does the model need next?” and act on it in the same week. That is what a generative data factory actually enables.
Ready to see what this architecture looks like in a production-ready system? Vivid 3D is built as a Visual Data Platform for Enterprise that unifies synthetic generation, automated ground truth, hybrid dataset workflows, and continuous optimization. So computer vision teams can move from static datasets to an operational loop. And if your organization also cares about downstream 3D applications like product configurators, the same controlled asset foundation can support those experiences as a secondary outcome. The primary win remains the same: visual data as a system, not a scramble.