
Synthetic Data Generation Methods: A Technical Guide for 2026

"Synthetic data" is not one thing. A GAN generating medical images, an LLM producing training dialogues, a rule engine fabricating bank transactions, and a 3D renderer producing product images for computer vision training - these are all synthetic data generation, but they work differently, fail differently, and suit completely different use cases.
The confusion matters because teams often pick a method based on what they've heard about rather than what fits the problem. This guide covers the main synthetic data generation methods in use in 2026 - what each one does, where it breaks down, and when it's the right choice. The goal is to make the method selection decision less about hype and more about engineering fit.
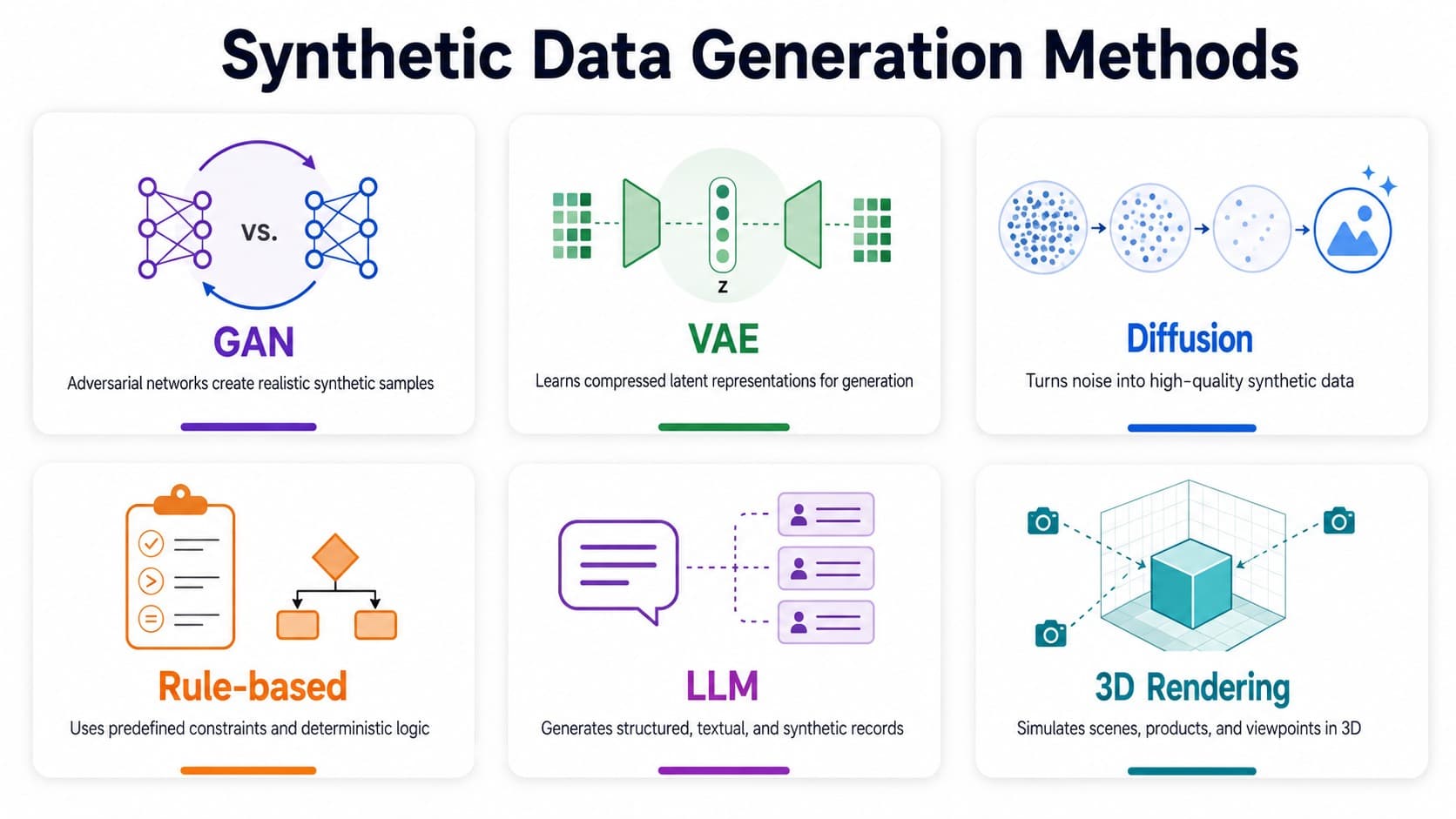
The main methods at a glance
- GANs (Generative Adversarial Networks) - generate realistic images, tabular data, and time-series by training a generator against a discriminator. High quality ceiling, unstable training.
- VAEs (Variational Autoencoders) - encode data into a latent space and decode new samples from it. More stable than GANs, lower peak quality.
- Diffusion models - generate high-quality images by iteratively denoising random noise. Currently the state of the art for image synthesis quality.
- Rule-based / statistical methods - generate data by sampling from defined distributions or applying explicit logic rules. Fast, predictable, low complexity - but only as good as the rules.
- LLM-based generation - use large language models to produce synthetic text, structured data, or instruction datasets. Highly flexible, but inherits the biases of the model.
- 3D rendering and simulation - generate photorealistic images from 3D scenes with programmatic control over lighting, angle, and materials. The standard method for visual AI training at scale.
Why Method Selection Matters More Than It Used To
Synthetic data generation has moved from a niche research technique to mainstream practice fast. Gartner projects that 75% of businesses will use generative AI to create synthetic data by 2026, up from less than 5% in 2023. That kind of adoption rate means a lot of teams are making method choices without deep experience in what breaks in production.
The stakes are real. A model trained on synthetic data generated by the wrong method for the use case will fail in ways that aren't obvious during training or testing - distribution mismatch shows up in deployment, not in benchmarks. Choosing the right generation method is a decision that compounds: it determines the quality ceiling of your training data, the cost of scaling, and how much real-world validation you need before trusting the output.
GANs - High Quality, Difficult to Train

Generative Adversarial Networks were, for several years, the dominant method for high-quality synthetic data generation in image and tabular domains. The architecture sets two networks against each other: a generator that produces synthetic samples and a discriminator that tries to distinguish them from real data. The generator improves by fooling the discriminator; the discriminator improves by catching the generator. In theory, they converge to a generator that produces indistinguishable synthetic data.
In practice, GAN training is unstable. Mode collapse - where the generator learns to produce a narrow range of outputs that fool the discriminator rather than covering the full distribution - is a persistent problem. Training requires careful hyperparameter tuning, and the results are sensitive to the quality and size of the training data. Small datasets produce poor GANs. Highly imbalanced datasets produce GANs that underrepresent minority classes.
When GANs work, they work well. For medical image synthesis, financial transaction generation, and certain time-series applications, GAN-based approaches have produced synthetic data that improves model performance measurably. The key is having enough real data to train the GAN in the first place - which creates a somewhat circular dependency. If you have enough real data to train a good GAN, you may have enough real data to train your downstream model directly.
Use when: You need high-fidelity synthetic images or tabular data and have sufficient real data (thousands of examples minimum) to train a stable generator.
Avoid when: Your real dataset is small, your distribution has rare classes you need to cover, or you need the generation process to be interpretable.
VAEs - Stable but Blurry
Variational Autoencoders approach generation differently. An encoder maps real data into a compressed latent space represented as a probability distribution rather than a fixed vector. A decoder then samples from that distribution and reconstructs data. New synthetic samples are generated by sampling from the latent space and decoding.
VAEs are more stable to train than GANs and less prone to mode collapse. The latent space is also interpretable in ways GAN latent spaces typically aren't - you can perform arithmetic on latent vectors and produce meaningful variations. For tabular data and certain structured generation tasks, VAEs produce reliable results with less tuning overhead.
The tradeoff is output quality. VAE-generated images tend to be blurrier than GAN outputs, because the reconstruction objective encourages the model to average plausible outputs rather than commit to a sharp prediction. For tasks where visual realism is critical - training computer vision models, generating product imagery - this quality ceiling matters. For tabular data, clinical records, or structured time-series, it matters much less.
Use when: You need stable, interpretable generation of tabular or structured data and training stability is more important than peak output quality.
Avoid when: Visual realism is the primary requirement, or you need the generated distribution to cover rare edges cases that VAE averaging will smooth out.
Diffusion Models - Current State of the Art for Images
Diffusion models have displaced GANs as the leading method for high-quality image synthesis. The approach works by progressively adding noise to real data during training, then learning to reverse that process - iteratively denoising a random noise sample into a realistic image. Stable Diffusion, DALL-E, and Midjourney are all diffusion-based.
The quality ceiling is higher than GANs, and the training is more stable. Diffusion models also support conditioning: you can generate images matching a text description, a class label, a reference image, or a combination. This makes them flexible for controlled synthetic data generation where you need specific content - particular object categories, specific scenes, particular visual styles.
The cost is compute. Diffusion model inference is slower than GAN inference because each sample requires many denoising steps. Generating millions of training images with a diffusion model is feasible but expensive. Fine-tuning or training from scratch requires significant GPU resources. For teams generating synthetic data at very large scale, the per-image compute cost is a real constraint.
Use when: You need photorealistic synthetic images with fine-grained control over content, and you have the compute budget to support diffusion inference at your required scale.
Avoid when: Speed and cost per sample are primary constraints, or you need deterministic, rule-governed generation rather than probabilistic sampling.
Rule-Based and Statistical Methods - Fast, Predictable, Limited
Not all synthetic data generation requires a neural network. Rule-based and statistical methods generate data by sampling from defined distributions, applying explicit business logic, or combining both. A rule-based generator for bank transaction data might define: transaction amounts drawn from a log-normal distribution, merchant categories sampled from weighted frequency tables, timestamps following day-of-week and hour-of-day patterns observed in real data.
These methods are fast, cheap, deterministic, and interpretable. You know exactly what rules produced the data. For software testing - generating realistic-looking data to populate a test database, validate an API, or run load tests - rule-based generation is usually the right choice. It doesn't require training data, it's easy to control, and the output is as realistic as the rules you write.
The limitation is that the rules have to come from somewhere. If you're generating data for a domain you understand well and the rules are explicit, this works. If you're trying to capture the subtle correlations and unexpected patterns in real user behavior, explicit rules will miss them. Rule-based synthetic data is good at generating plausible data; it's less good at generating data that captures the genuine complexity of a real distribution.
Use when: Software testing, data masking, database population, or any application where explicit business rules define the valid data space and you don't need to learn from real data.
Avoid when: You need the synthetic data to capture learned patterns from real data that you can't express as explicit rules.
LLM-Based Generation - Flexible but Inherited Bias
Large language models can generate synthetic text, structured data, instruction-following pairs, and question-answer datasets at scale. This has become a common approach for training and fine-tuning downstream NLP models - particularly for tasks where labeled data is expensive to collect, like specific domain question-answering, specialized instruction following, or multilingual training data augmentation.
The practical advantage is flexibility. An LLM can generate synthetic data in almost any format, across almost any domain, with minimal setup. The quality is often good enough for training purposes - certainly better than nothing, and faster and cheaper than human annotation for many tasks.
The known risk is bias amplification. An LLM generating synthetic training data reproduces the patterns and biases in its own training data. If you fine-tune a model on LLM-generated data and then evaluate it against real-world inputs, you may find that the model performs well on the synthetic distribution and poorly on genuine user behavior - particularly for edge cases, non-standard language, or inputs from demographic groups underrepresented in the LLM's training data.
There's also the collapse risk: a model fine-tuned on its own synthetic outputs and then used to generate more synthetic data for the next training iteration can progressively drift from the real-world distribution. This is an active research area, not a solved problem.
Use when: Augmenting labeled training data for NLP tasks, generating instruction-tuning datasets, or producing structured text data where the format is well-defined and bias risks are understood.
Avoid when: The task requires capturing genuine human behavior that differs from the LLM's learned patterns, or when iterative self-distillation creates compounding distribution drift.
3D Rendering and Simulation - The Standard for Visual AI at Scale

For computer vision tasks - object detection, product recognition, quality inspection, AR placement, autonomous vehicle perception - 3D rendering and physics simulation have become the standard approach to generating training data at scale. The method is conceptually simple: build or acquire 3D models of the objects you need your model to recognize, then render them programmatically across a controlled range of lighting conditions, camera angles, backgrounds, and occlusions.
The advantages over other synthetic generation methods are significant for visual use cases. Rendering is deterministic: you specify exactly what you want in each image and the renderer produces it. Scale is limited only by compute: generating one million images of a product across all relevant conditions is a matter of setting parameters and waiting, not annotating a million photographs. Rare conditions - unusual lighting, specific occlusion patterns, low-resolution captures - can be generated deliberately rather than waiting for them to occur in real data collection.
For product-related visual AI, the pipeline typically looks like this: start with a 3D model of the product (from CAD files, photogrammetry, or purpose-built 3D content), configure the render parameters to cover the real-world conditions the model will encounter, generate a large synthetic training set, and validate on a smaller set of real images before deployment.
This is exactly the workflow behind Vivid3D's Simulation Generator: the same 3D assets used to power a product configurator can generate synthetic training datasets for visual AI. A product that exists as a governed 3D model for ecommerce configuration also becomes the source for the computer vision training data used to recognize it in AR or quality inspection workflows. One asset, two downstream uses - without duplication.
The known challenge is sim-to-real transfer: models trained on synthetic renders don't always generalize perfectly to real camera images, because rendering engines and physical cameras differ in texture statistics, noise characteristics, and lighting behavior. The gap has narrowed significantly as rendering quality has improved, and fine-tuning on a small real dataset after synthetic pre-training has become the standard approach to closing it.
Use when: Training computer vision models for product recognition, AR, quality inspection, or any visual task where photographing all required variations is impractical or impossible.
Avoid when: You need the model to handle visual characteristics - specific sensor noise, real-world texture variation - that your rendering pipeline doesn't replicate accurately, and you can't bridge the gap with real-data fine-tuning.
For more context on how synthetic visual data fits into the broader picture of AI training data decisions, see our piece on synthetic data vs real data.
Method Comparison at a Glance
How to Choose the Right Method
The choice reduces to three questions that don't have universal answers.
What data type are you generating?
Images and video: diffusion models for highest quality, 3D rendering for visual AI at scale with programmatic control. Tabular and time-series: GANs or VAEs if you have real data to train from, rule-based methods if your domain is well-defined and you don't. Text and structured language data: LLM-based generation, with careful attention to bias and drift. Mixed: most production systems combine methods - synthetic images from rendering, synthetic metadata from rule-based generation, assembled into a complete training dataset.
Do you have enough real data to train a generative model?
GANs, VAEs, and diffusion models all require real data to learn from. If your real dataset is small - hundreds of examples rather than thousands - the generative model will be poor and the synthetic data will be worse than useless. Rule-based generation and 3D rendering don't require real training data: they generate from explicit specifications. For early-stage products or genuinely rare scenarios, these methods are often the only practical options.
What happens when the synthetic distribution doesn't perfectly match reality?
Some tasks tolerate distribution mismatch better than others. A software test suite that fails on synthetic data but would have passed on real data is a nuisance. A medical AI model that performs well on synthetic data but fails on real patient images is a serious problem. The higher the stakes of distribution mismatch, the more real-world validation you need regardless of which generation method you use - and the more conservatively you should approach deploying a model trained predominantly on synthetic data.
FAQ
What is the most common synthetic data generation method?
It depends on the domain. For tabular data and structured records, rule-based methods and VAE-based approaches are most common in production. For images, 3D rendering is the dominant approach for product and object recognition tasks, while diffusion models are increasingly used for higher-complexity visual generation. For text and NLP tasks, LLM-based generation has become standard for augmenting training datasets. There's no single dominant method across all use cases - the right choice depends on data type, available real data, and quality requirements.
What is a GAN and how does it generate synthetic data?
A GAN (Generative Adversarial Network) consists of two neural networks trained simultaneously: a generator that produces synthetic data samples and a discriminator that tries to classify samples as real or synthetic. The generator improves by producing samples the discriminator can't distinguish from real data; the discriminator improves by catching synthetic samples. At convergence, the generator produces data statistically similar to the real training set. In practice, GAN training is unstable and prone to mode collapse, where the generator learns to produce a narrow subset of plausible outputs rather than covering the full distribution.
How is synthetic data generated for computer vision?
The standard approach for product and object recognition is 3D rendering: building or acquiring 3D models of the target objects and rendering them programmatically across controlled variations in lighting, camera angle, background, and occlusion. This produces labeled training images at scale without photography. Diffusion models are also used to generate synthetic images for computer vision, particularly when 3D models aren't available. Both approaches require real-world validation to confirm the synthetic distribution generalizes to real camera images before deployment.
What is the difference between GAN and diffusion model generation?
GANs generate samples in a single forward pass through the generator network - fast inference, but unstable training and prone to mode collapse. Diffusion models generate samples by iteratively denoising a random noise sample over many steps - stable training and higher output quality, but slower inference and higher compute cost per sample. For high-quality image synthesis in 2026, diffusion models have largely replaced GANs as the preferred method. For tabular and structured data, GANs and VAEs remain common because the quality advantage of diffusion models is less significant for non-image data.
Can synthetic data be used for LLM training?
Yes, and it already is at scale. Synthetic instruction-following data, question-answer pairs, and domain-specific text are commonly used to fine-tune and align LLMs. The risk is model collapse: if a model is fine-tuned on its own synthetic outputs and then used to generate more synthetic data for the next iteration, the distribution progressively drifts from real human language. Research on this risk is active - current best practice is to mix synthetic and real data rather than replacing real data entirely, and to monitor distribution drift across training iterations.
How does 3D rendering compare to GAN-based image generation for AI training?
For product and object recognition tasks, 3D rendering has practical advantages over GANs: it doesn't require a large real training dataset to build the generator, it offers precise programmatic control over every image parameter, and it scales cheaply once the 3D models exist. GANs learn from real data and can produce more photorealistic outputs in some domains - but for training computer vision models on specific products or objects, rendering from 3D models is typically the faster, cheaper, and more controllable approach. The sim-to-real gap is the main challenge: models trained on renders need real-data validation before deployment.


.png)


